
A Clinical Machine Learning Operations (MLOps) Maturity Framework For Biopharma
By Partha Anbil and Anoop Siddharthan

Clinical trial data management has entered a period of structural discontinuity. The convergence of decentralized trial architectures, wearable-derived data streams, genomic co-primaries, and AI-assisted operational workflows has generated a data environment of qualitatively greater complexity than the systems presently governing it. The global average cost of Phase 3 development programs now exceeds $1.2 billion, a figure that does not capture the opportunity cost of timeline extensions attributable to data quality failures — estimated by independent analyses to contribute to approximately 25% of trial delays.
Against this backdrop, the pharmaceutical industry has invested substantially in machine learning applications spanning query prediction, anomaly detection, risk signal generation, and protocol digitization. Yet, investment in the operational infrastructure to sustain these models in production — the MLOps layer — has lagged significantly. The result is a widening gap between the potential value of clinical AI and its realized operational contribution.
Across a survey of 47 pharmaceutical organizations, fewer than 12% reported having formal drift detection mechanisms for production clinical AI models. The remaining 88% were unable to characterize model performance degradation between deployment and database lock — a period spanning, on average, 28 months for Phase 3 programs.
The Clinical MLOps Lifecycle: A Five-Stage Framework
Drawing on established MLOps frameworks and the specific governance requirements of regulated clinical environments, we propose a five-stage Clinical MLOps lifecycle that maps the journey from raw trial data to validated, audit-ready model outputs.
Stage I: Data Engineering and Feature Governance
The clinical feature store — a versioned, centralized repository of predictive signals derived from EDC, CTMS, and external data sources — constitutes the foundational data layer of the Clinical MLOps framework. Unlike commercial AI deployments, clinical feature engineering must be reproducible to a regulatory standard, and each feature transformation must be documented, version-controlled, and traceable to source data with the same rigor applied to any derived dataset in a regulatory submission. Organizations deploying feature stores report a median 43% reduction in duplicated feature engineering effort across model teams (internal benchmarking data, range 28-61%).
Stage II: Experiment Tracking and Model Provenance
The reproducibility crisis documented in computational biology (Baker, 2016; Nat. Methods) has a clinical AI analogue: models deployed into production that cannot be reproduced from documented training artefacts. Experiment tracking infrastructure that logs every training run — its data inputs, hyperparameter configuration, validation performance, and output artefacts — creates the provenance record that both scientific reproducibility and regulatory inspection require. The analogy to GLP documentation of experimental conditions is deliberate and apt.
Stage III: Continuous Validation and Regulatory Interface
Traditional Computer System Validation frameworks, codified in GAMP 5 and implemented under 21 CFR Part 11, treat software validation as a discrete event preceding deployment. Machine learning systems subject to continuous retraining challenge this paradigm structurally. We propose a continuous validation architecture in which automated validation test suites - encompassing performance benchmarks, bias assessments, and edge-case test batteries pre-specified in a validation master plan - are triggered programmatically upon each model update. This approach is conceptually aligned with the FDA's proposed Predetermined Change Control Plan framework for AI/ML-based Software as a Medical Device.
Stage IV: Model Serving and Clinical System Integration
Production deployment of clinical AI models requires integration with operational data flows at the point of clinical activity. Event-driven architectures — in which EDC data entry events trigger real-time model inference — represent a significant advance over batch-processing paradigms, enabling in-workflow risk flagging rather than retrospective anomaly detection. The technical requirements for low-latency model serving at global trial scale impose infrastructure demand that most clinical data platforms are only beginning to address.
Stage V: Observability, Drift Detection, and Adaptive Retraining
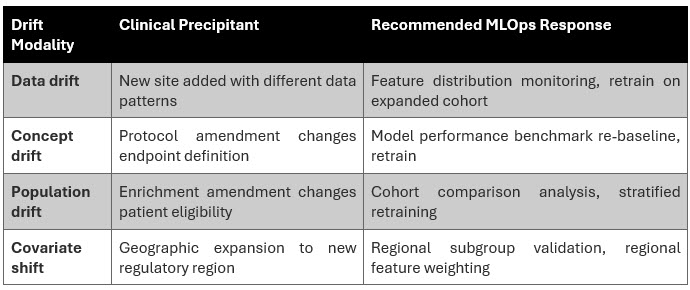
We identify two primary drift modalities of clinical significance: (i) data drift, characterized by statistical distributional shifts in input features arising from site-level behavioral changes or protocol amendments; and (ii) concept drift, reflecting changes in the underlying relationship between predictive features and the clinical outcomes the model is trained to detect. Both modalities are empirically documented in longitudinal analyses of clinical AI deployments but are systematically under monitored in current practice. Adaptive retraining pipelines that trigger model updates in response to drift threshold breaches — subject to continuous validation controls — represent the current state of the art in clinical MLOps observability.
What MLOps Actually Means & Why It Changes Everything
MLOps borrows its philosophy from the DevOps movement that transformed software engineering two decades ago. The insight was simple but powerful: Building software is not enough. You need the infrastructure to deploy it reliably, update it continuously, and monitor it in production. MLOps applies this same logic to AI.
You Don't Know When Your Models Break
AI models degrade when the world changes around them and in a multi-year clinical trial, the world changes constantly. New sites join with different data patterns. Protocols are amended. Patient populations shift. Without continuous monitoring and drift detection, models degrade invisibly. By the time the problem is visible in data quality metrics, significant damage has already been done.
The MLOps solution: automated model observability that tracks prediction performance and feature distributions in real time, triggering alerts and retraining pipelines when drift thresholds are crossed.

Regulators Are Catching Up Faster Than You Think
The FDA's Digital Health Center of Excellence and ICH E6(R3) guidance framework are converging in a regulatory environment where AI systems used in clinical operations must be explainable, continuously monitored, and validated in a way that survives inspection. The agency's proposed Predetermined Change Control Plan framework envisions pre-approved protocols for how AI models can be updated in production — a regulatory pathway that rewards organizations with mature MLOps infrastructure and penalizes those without it.
In three to five years, a clinical AI deployment without formal drift monitoring and continuous validation documentation will be a liability at FDA interaction, not an asset.
5 Decisions Every Biopharma Needs To Make
1. Treat model governance as a board-level risk, not an IT project.
AI models influencing patient safety decisions and regulatory submissions are material corporate risks. Embrace model risk management, a discipline long established in financial services and belongs on the agenda of ClinOps leadership alongside safety, quality, and compliance. Establish a clinical model risk management committee with cross-functional executive membership and clear accountability for model performance outcomes.
2. Invest in a clinical feature store before your next model.
The single highest-leverage infrastructure investment in clinical MLOps is a centralized, versioned feature store: a repository of the predictive signals, such as site performance metrics, patient compliance indicators, and data quality rates that AI models across your organization depend on. Without it, every model team re-engineers the same features independently, inconsistently, and without the version control that regulatory inspection and model reproducibility require. With it, every model benefits from every previous team's work.
3. Automate validation or be left behind.
Traditional Computer System Validation is a bottleneck for continuously retrained AI. Organizations successfully navigating this challenge are those creating automated validation test suites. These include predefined performance benchmarks, bias checks, and tests for unusual scenarios that are run automatically with each model update. This is not cutting corners on validation. It is applying the principles of quality engineering to the validation process itself.
4. Build the talent you cannot hire
The MLOps-clinical hybrid professional — someone who understands both the statistical monitoring requirements of ICH E6(R3) and the drift detection architecture of a Kubernetes-hosted model serving platform — is often hard to find on the open market in meaningful numbers. Organizations that are winning this talent battle are building structured reskilling programs that develop experienced clinical data managers (CDMs) and biostatisticians into MLOps-capable clinical data scientists. This investment compounds: It creates institutional knowledge that walks in the door every morning.
5. Choose your platform partners on MLOps readiness, not legacy relationships.
The EDC and clinical data platform selection decisions being made today will determine MLOps capability for the next seven to 10 years. Platforms built on legacy architectures — batch data exports, closed APIs, and/or no native feature store integration — will not support the real-time data pipelines that production clinical MLOps requires. MLOps readiness — streaming EDC APIs, native drift monitoring dashboards, model deployment integration, and regulatory audit trail for AI outputs — must be a primary evaluation criterion alongside the traditional axes of user experience and regulatory compliance.
Conclusion
The productive deployment of AI in clinical data operations is contingent on the maturation of MLOps infrastructure commensurate with the regulatory, patient safety, and scientific rigor requirements of the clinical environment. Organizations that treat MLOps as a production engineering discipline, investing in feature governance, continuous validation, drift monitoring, and adaptive retraining will achieve durable AI performance advantages that compound across trial programs and therapeutic areas.
The industry stands at an inflection point: The foundational engineering choices made in the next three to five years will determine the AI operational capabilities available for the next generation of clinical development programs.
The question for every pharma and biotech executive is not whether to deploy AI in clinical data operations. That decision has already been made, implicitly or explicitly, by the competitive environment.
The question is whether the AI your organization deploys will still be working accurately, reliably, and defensibly two years after deployment. Most current clinical AI deployments likely do not meet this standard. MLOps is the answer to that problem, and the time to build it is before the next trial, not after it fails.
Authors’ Note: The views expressed in the article are those of the authors and not of the organizations they represent.
References:
- Baker M. (2016). 1,500 scientists lift the lid on reproducibility. Nature, 533(7604), 452–454.
- DiMasi JA, Grabowski HG, Hansen RW. (2016). Innovation in the pharmaceutical industry: New estimates of R&D costs. J Health Econ, 47, 20–33.
- FDA. (2021). Artificial Intelligence/Machine Learning (AI/ML)-Based Software as a Medical Device (SaMD) Action Plan. U.S. Food and Drug Administration.
- FDA. (2024). Predetermined Change Control Plans for Artificial Intelligence-Enabled Device Software Functions. Draft Guidance. U.S. Food and Drug Administration.
- ICH. (2023). Integrated Addendum to ICH E6(R2): Guideline for Good Clinical Practice E6(R3). International Council for Harmonisation.
- ISPE. (2022). GAMP 5: A Risk-Based Approach to Compliant GxP Computerized Systems, Second Edition. International Society for Pharmaceutical Engineering.
- Kreuzberger D, Kühl N, Hirschl S. (2023). Machine Learning Operations (MLOps): Overview, Definition, and Architecture. IEEE Access, 11, 31866–31879.
- Sculley D et al. (2015). Hidden Technical Debt in Machine Learning Systems. Advances in Neural Information Processing Systems (NeurIPS), 28.
- Wouters OJ, McKee M, Luyten J. (2020). Estimated Research and Development Investment Needed to Bring a New Medicine to Market. JAMA, 323(9), 844–853.
About The Author:
 Partha Anbil is at the intersection of the life sciences industry and management consulting. He is currently an industry advisor, life sciences, at MIT, his alma mater. He held senior leadership roles at WNS, IBM, Booz & Company, Symphony, IQVIA, KPMG Consulting, and PWC. Mr. Anbil has consulted with and counseled health and life sciences clients on structuring solutions to address strategic, operational, and organizational challenges. He was a member of the IBM Industry Academy, a highly selective group of professionals inducted by invitation only, the highest honor at IBM. He is a healthcare expert member of the World Economic Forum (WEF).
Partha Anbil is at the intersection of the life sciences industry and management consulting. He is currently an industry advisor, life sciences, at MIT, his alma mater. He held senior leadership roles at WNS, IBM, Booz & Company, Symphony, IQVIA, KPMG Consulting, and PWC. Mr. Anbil has consulted with and counseled health and life sciences clients on structuring solutions to address strategic, operational, and organizational challenges. He was a member of the IBM Industry Academy, a highly selective group of professionals inducted by invitation only, the highest honor at IBM. He is a healthcare expert member of the World Economic Forum (WEF).
 Anoop Sidharthan is practitioner of enterprise technology architecture and digital transformation with deep specialization in cloud, generative AI, and healthcare & life sciences. He brings over experience spanning architecture leadership roles at Cognizant, L&T Infotech. Mr. Anoop has architected and delivered large-scale transformation programs exceeding $500 million, counseling global enterprises on cloud modernization, multi-cloud strategy, and AI-driven solutions across payer, provider, life sciences, and pharma domains. He has led technology implementations across the U.S., UK, Australia, and India and is a trusted advisor to business and IT stakeholders on enterprise architecture and healthcare ecosystem integration.
Anoop Sidharthan is practitioner of enterprise technology architecture and digital transformation with deep specialization in cloud, generative AI, and healthcare & life sciences. He brings over experience spanning architecture leadership roles at Cognizant, L&T Infotech. Mr. Anoop has architected and delivered large-scale transformation programs exceeding $500 million, counseling global enterprises on cloud modernization, multi-cloud strategy, and AI-driven solutions across payer, provider, life sciences, and pharma domains. He has led technology implementations across the U.S., UK, Australia, and India and is a trusted advisor to business and IT stakeholders on enterprise architecture and healthcare ecosystem integration.